Jetzt habe ich schon einen neuen Rechner, kann aber natürlich nicht sagen, wie ich ihn im Normalbetrieb auslaste. Dass die NVMe-Performance sehr gut ist, habe ich ja bereits geschrieben.
Um es vorweg zu nehmen: Gar nicht!
Mehr über den neuen Rechner herauszufinden, ist aber eine gute Gelegenheit, sich einmal mit Prometheus und Grafana auseinanderzusetzen. Im Rahmen der Beschäftigung damit war sehr positiv überrascht, wie leicht das alles ist, zumindest in diesem einfachen Fall.
Disclaimer: Bitte versteht das folgende als "Proof of Concept", um schnell zu einem Ergebnis zu kommen. Benutzt es bitte nicht für ein Produktionssetup auf Servern im Internet.
Ganz bewusst nutze ich keine Pakete, sondern die Binaries von den Webseiten der Hersteller. Wenn ich das Experiment beende, können die Daten und Installationen sehr schnell gelöscht werden.
Hier werde ich keine Einführung in Prometheus geben, dafür gibt es zahlreiche Webseiten, die das schon sehr ausführlich gemacht haben. Für dieses Setup muss man nur so viel wissen, dass Prometheus selber die zentrale Komponente ist, die in regelmässigen einstellbaren Abständen, Daten von den Exportern sammelt und in eine eigene "Time series database" schreibt. Der Node Exporter stellt Daten über Diskbelegung, I/O-Verhalten, CPU, Load, ... und vieles andere mehr zur Verfügung. Grafana greift auf diese gesammelten Daten zu und bereitet sie grafisch in Dashboards auf.
Der Spass beginnt mit der Anlage des Users, mit dem alles laufen soll.
# adduser --system --home /srv/monty --shell /sbin/nologin monty
Danach folgt der Download der nötigen Archive von der Prometheus Download Seite und der Grafana Downloadseite (die ist ein bisschen versteckt).
# mkdir /srv/monty/archive
# cd /srv/monty/archive
# curl -LO https://github.com/prometheus/prometheus/releases/download/v2.26.0/prometheus-2.26.0.linux-amd64.tar.gz
# curl -LO https://github.com/prometheus/node_exporter/releases/download/v1.1.2/node_exporter-1.1.2.linux-amd64.tar.gz
# curl -LO https://dl.grafana.com/oss/release/grafana-7.5.3.linux-amd64.tar.gz
Die einzelnen Archive werden ausgepackt und es wird jeweils ein Link auf das ausgepackte Archiv gesetzt. Das macht das Update deutlich einfacher.
# cd /srv/monty
# tar xzf archive/prometheus-2.26.0.linux-amd64.tar.gz
# tar xzf archive/node_exporter-1.1.2.linux-amd64.tar.gz
# tar xzvf archive/grafana-7.5.3.linux-amd64.tar.gz
# ln -s grafana-7.5.3 grafana
# ln -s node_exporter-1.1.2.linux-amd64 node_exporter
# ln -s prometheus-2.26.0.linux-amd64 prometheus
Jetzt noch schnell je ein Verzeichnis für die Grafana- und die Prometheus-Daten anlegen und die mitgelieferten Konfigurationen kopieren. Der Nodeexporter ist "dumm", der plappert wie ein Wasserfall, wenn er gefragt wird.
# cd /srv/monty
# mkdir promdata grafdata
# cp prometheus/prometheus.yml promdata
# cp grafana/conf/defaults.ini grafdata/grafana.ini
In der grafana.ini-Datei sind die folgenden Änderungen vorzunehmen, alles andere muss nicht angefasst werden:
data = /srv/monty/grafdata
logs = /srv/monty/grafdata/log
plugins = /srv/monty/grafdata/plugins
provisioning = /srv/monty/grafdata/provisioning
An die prometheus.yml-Datei muss man nur die folgenden Zeilen hinter - targets: ['localhost:9090'] anhängen:
- job_name: 'terrania'
scrape_interval: 5s
static_configs:
- targets: ['localhost:9100']
Der Name ist natürlich frei. Prometheus und Node Exporter arbeiten sehr ressourcenarm, daher kann man durchaus alle 5 Sekunden (oder noch öfter) Werte nehmen. Weitere Exporter werden einfach an das Ende der Datei angehängt. Das Standard-Abfrageintervall sind 15 Sekunden.
Abschliessend noch dem User monty alle Dateien und Verzeichnisse übereignen.
# chown -R monty /srv/monty
Bleibt noch systemd, bitte kopiert die folgenden Service-Files nach /etc/systemd/system und führt danach ein systemd daemon-reload aus.
# /etc/systemd/system/node_exporter.service
[Unit]
Description=Node Exporter
Wants=network-online.target
After=network-online.target
[Service]
User=monty
WorkingDirectory=/srv/monty/node_exporter
Type=simple
ExecStart=/srv/monty/node_exporter/node_exporter
[Install]
WantedBy=multi-user.target
Bitte beachtet, dass nach den Backslashes "\" nur das Zeilenende kommen darf.
# /etc/systemd/system/prometheus.service
[Unit]
Description=Prometheus
Wants=network-online.target
After=network-online.target
[Service]
User=monty
Type=simple
WorkingDirectory=/srv/monty/prometheus
ExecStart=/srv/monty/prometheus/prometheus \
--config.file /srv/monty/promdata/prometheus.yml \
--storage.tsdb.path /srv/monty/promdata \
--web.console.templates=/srv/monty/prometheus/consoles \
--web.console.libraries=/srv/monty/prometheus/console_libraries
[Install]
WantedBy=multi-user.target
# /etc/systemd/system/grafana.service
[Unit]
Description=Grafana
Wants=network-online.target
After=network-online.target
[Service]
User=monty
WorkingDirectory=/srv/monty/grafana
Type=simple
ExecStart=/srv/monty/grafana/bin/grafana-server \
-config /srv/monty/grafdata/grafana.ini \
-homepath /srv/monty/grafana \
web
[Install]
WantedBy=multi-user.target
Die Services werden der Reihe nach gestartet und aktiviert.
# systemctl enable --now node_exporter
# systemctl enable --now prometheus
# systemctl enable --now grafana
Eventuell auftretende Fehler systemctl status node_exporter prometheus grafana sollten natürlich behoben werden.
Grafana lässt sich nun über localhost:3000 aufrufen. Im Standard sind Username und Passwort auf "admin" gesetzt.
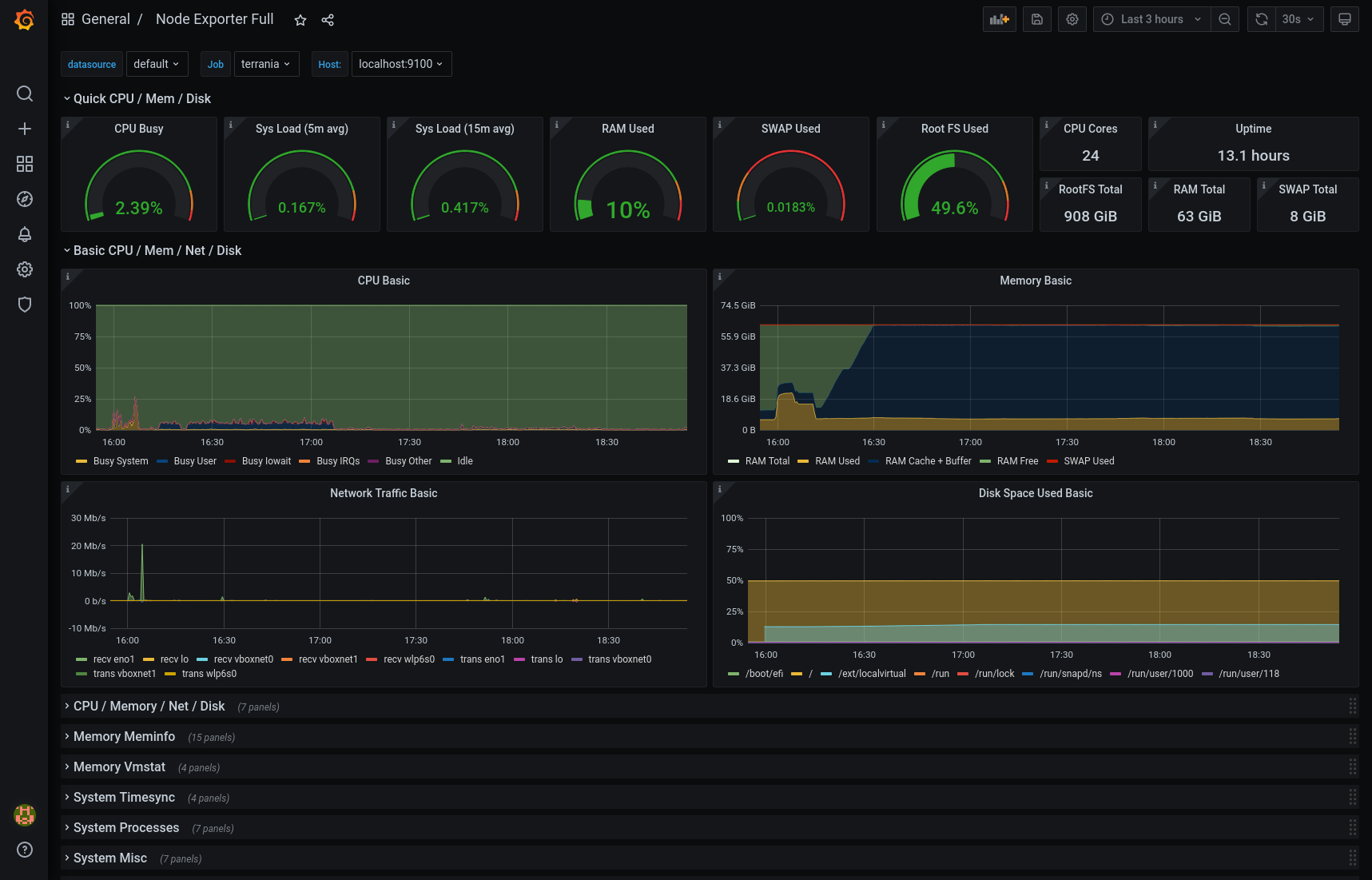
Um die ersten bunten Bilder zu sehen, muss noch eine Datasource und ein Dashboard angelegt werden.
Als Datasource solltet Ihr über das Zahnrad und "Data Sources" den Eintrag "Prometheus" auswählen. Prometheus hört standardmässig auf Port 9090, ich musste die komplette URL angeben, das "Scrape interval" habe ich auf "5s" gesetzt.
Als Dashboard empfehle ich den Import von 1860 und die Angabe der gerade konfigurierten Datenquelle Prometheus.
Ich wundere mich immer wieder, dass die CPU-Werte ganz oben angezeigt werden und nicht die aussagekräftigere "System Load".
Abschliessende Anmerkung: Einige von Euch wundern sich vermutlich über die Links, die ich gesetzt habe. Als ich den Artikel geschrieben habe, habe ich auch gleich ein Update von Prometheus und Grafana eingespielt, das funktioniert wie folgt:
# cd /srv/monty/archive
# curl -LO https://github.com/prometheus/prometheus/releases/download/v2.26.0/prometheus-2.26.0.linux-amd64.tar.gz
# curl -LO https://dl.grafana.com/oss/release/grafana-7.5.3.linux-amd64.tar.gz
# cd ..
# tar xzf prometheus-2.26.0.linux-amd64.tar.gz
# tar xzf grafana-7.5.3.linux-amd64.tar.gz
# systemctl stop grafana
# rm grafana
# ln -s grafana-7.5.3 grafana
# systemctl start grafana
# systemctl stop prometheus
# rm prometheus
# ln -s prometheus-2.26.0.linux-amd64 prometheus
# systemctl start prometheus
Wenn man das alles in eine Zeile schreibt, dauert der Teil Stoppen, Link ändern und Starten deutlich unter einer Sekunde.
Viel Spass, bin gespannt auf Eure Kommentare.

