Im Zuge dessen, dass mein altes Dokumentationssystem mittels Wikis schon stark in die Jahre gekommen ist und ehrlicherweise nie so richtig gut funktioniert hat, habe ich mich von der TILpod-Community bei Matrix einmal inspirieren lassen.
Dort wurde Obsidian empfohlen, was mir aufgrund der Tatsache, dass es Closed-Source-Software ist, nicht so wirklich gefallen hat. In diesem Artikel bei GNULinux.ch wurde ich dann auf Logseq aufmerksam, was ich mir näher angeschaut habe.
Für eine sprachliche Auseinandersetzung mit dem Thema im Rahmen eines Podcasts empfehle ich Euch die März-Episode des TILpod.
Dokumentationsmedien, dazu zähle ich auch Wikis, haben meist ein Problem. Sie erlauben es selten, Informationen einfach so zu erfassen, ohne sich grosse Gedanken über die Struktur und die Findbarkeit machen zu müssen.
Notizen bestehen, zumindest bei mir, aus Stichpunkten, die nicht weiter ausformuliert sind. Ich mache sie am liebsten handschriftlich, weil mir das alle Freiheiten bietet und auch erlaubt, etwas "ins Unreine" zu skizzieren. Tools schränken zumeist die Möglichkeiten für Notizen ein, da sie an Programmvorgaben und Formen gebunden sind. Mobil auf dem Handy benutze ich Nextcloud Notes für Notizen, dafür gibt es eine sehr gute Android-App. Ich spiele mit dem Gedanken, eine Diktierfunktion oder sogar ein Diktiergerät zu verwenden.
Der Nachteil dieses Verfahrens ist, dass ich die Notizen noch einmal durchgehen muss, um sie in eine lesbare und verstehbare Form zu bringen.
Der Vorteil ist, dass ich die Notizen noch einmal durchgehe und die Inhalte besser behalten kann und dass mir durch die erneute Beschäftigung vielleicht noch weitere Inhalte und Themen einfallen.
Logseq versucht jetzt genau diese Lücke zwischen Notizen und Dokumentation zu schliessen. Vorab ein Disclaimer: Ich nutze das Tool erst seit rund einem Monat, bin noch ziemlicher Anfänger und nutze nur einen Bruchteil der Möglichkeiten.
Logseq ist noch im Beta-Modus und es gibt Anwendungen für Linux, Mac OS, Windows und Android. Es gibt auch noch eine Webanwendung, die die Daten in einem GitHub-Repository speichert, die soll aber eingestellt werden, sobald die Android-Anwendung fertig ist. Ach ja, mit einer weiteren Webanwendung aka "Live Demo", mit der kann man ohne weitere Installationen auch mit den lokalen Daten arbeiten. Obsidian und Logseq können auf derselben Verzeichnis-Hierarchie parallel zusammenarbeiten.
Ich habe Logseq via Flatpak auf zwei Linux-Maschinen installiert und zusätzlich auf einem Windows-System. Die Daten von Logseq können via Nextcloud synchronisiert werden, was in meinem Fall ohne weitere Zwischenfälle geklappt hat.
Basis von Logseq ist das Journal, in Form von "was ich heute getan habe". Man kann auch anders damit umgehen, aber das ist der einfachste Weg.
Innerhalb des Journals gibt es für jeden Tag eine Seite (gespeichert im Markdown-Format, Emacs Org-Mode wäre auch möglich), auf der man in Form einer Aufzählung alles notiert, was von Interesse ist. Dabei kann man Tags verwenden. Jeder Aufzählungspunkt und eventuelle weitere Unterpunkte gelten als Blöcke.
Klickt man auf einen Tag, bekommt man alle Blöcke angezeigt, die diesen Tag enthalten. Wenn man auf der "Tag-Seite" weitere Informationen erfasst, so wird auch diese im Markdown-Format abgelegt, ansonsten existiert die Seite nur virtuell.
Beispiel:
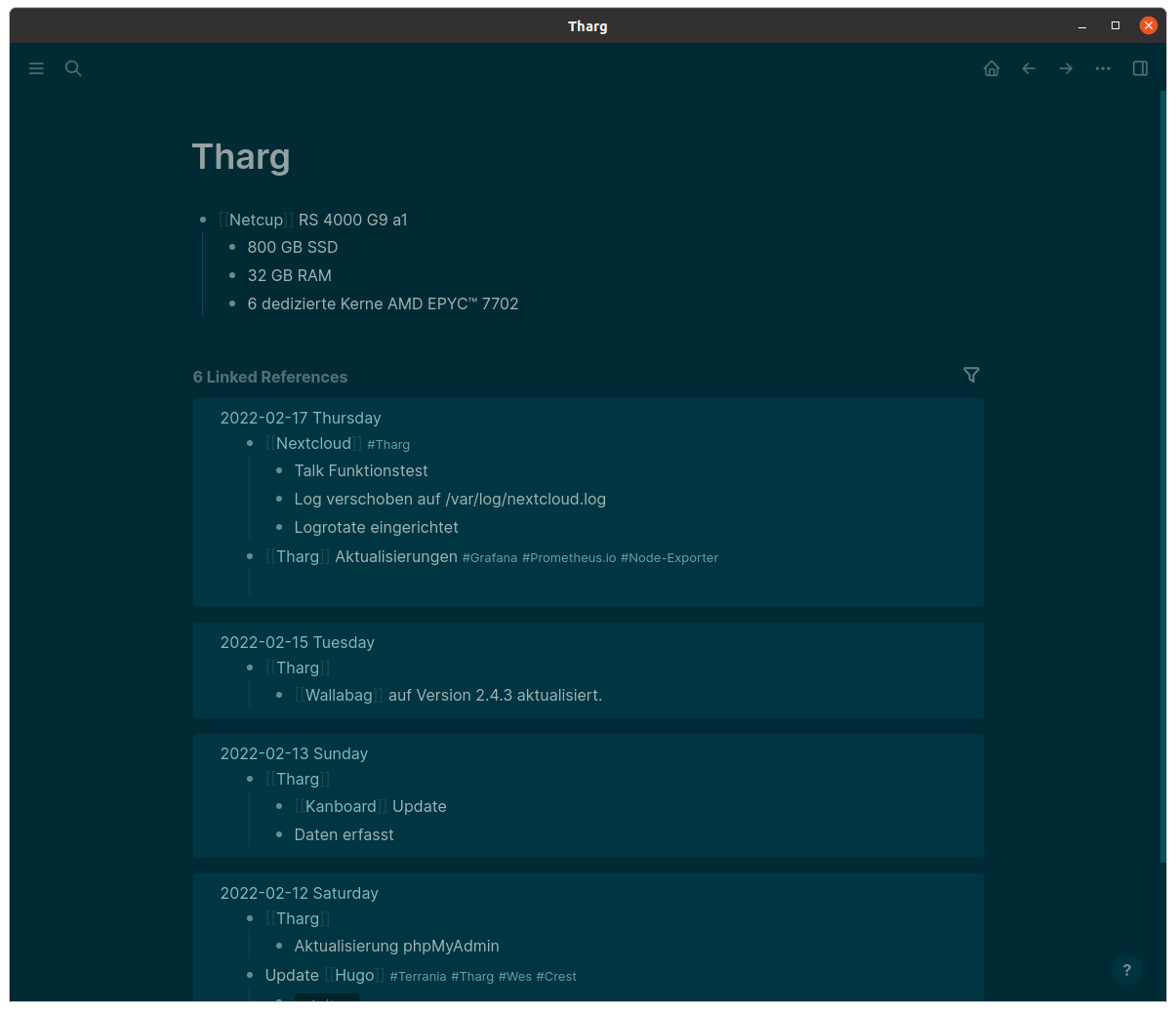
Ich beginne einen Block mit dem Namen eines meiner Rechner in doppelten eckigen Klammern (ich könnte auch das Hash-Zeichen "#" verwenden, das führt zum gleichen Resultat). Innerhalb des Blocks schreibe ich auf, was ich auf dem Rechner getan habe, beispielsweise "Logseq installiert". Logseq bekommt auch einen Tag.
Wenn ich auf den Rechnernamen klicke, bekomme ich alles gezeigt, was ich auf dem Rechner gemacht habe. Wenn ich auf Logseq klicke, bekomme ich alle Informationen und alle Installationen mit Bezug auf Logseq angezeigt.
Auf der Seite des Rechners erfasse ich beispielsweise die Hardwareausstattung.
Auf diese Art entsteht über die Zeit eine stark vernetzte Dokumentation. Man kann Bilder einfügen, Videos einbetten und sogar PDFs kommentieren. Mit der Speicherung der Daten kommt man nicht in Berührung, man muss nur beim ersten Start einen Speicherort in Form eines Verzeichnisses angeben.
Ich gewöhne mich gerade daran und bin ziemlich begeistert, dass die Software so gar nicht im Weg steht.
Wenn Ihr sie auch testen wollte, empfehle ich Euch den Logseq Intro Course mit acht kurzen Videos.
Ein Wermutstropfen ist für mich, dass sich die Entwickler "Privacy First" auf die Fahne geschrieben haben, aber per Default Telemetriedaten versenden. Das könnte man auch beim ersten Start abfragen.
Die Software ist FLOSS und soll es auch bleiben. Es ist eine Pro-Version geplant, die eine Synchronisationslösung eingebaut hat, ab dann lohnt sich vielleicht auch die Android-Anwendung.
Ich benutze Logseq für
- Engineering Journal
- Sammlung von Links, Bildern und Videos - könnte meine Bookmarks mit Shaarli ablösen.
- Installationen und Konfigurationen auf meinen Clients und Servern
- Planung von Vorträgen und Workshops
- Wissensspeicher
Was ich noch ganz spannend finde, ist die eingebaute Aufgabenverwaltung, die ich mir auch noch näher anschauen möchte. Spannend wäre es, ob ich damit Todoist ablösen könnte und ich alle Daten unter eigener Kontrolle hätte.
