Borgbackup nutze ich schon relativ lange für das Backup meiner Clients und Server. Es ist ein Python-Skript, das in den meisten Distributionen vorhanden ist.
Neben anderen tollen Features sind die drei besonderen Stärken von Borgbackup für mich:
- Geschwindigkeit: Borgbackup ist sehr schnell, sodass man auch "mal eben" ein Backup machen kann (auf meinen Servern läuft es zweimal pro Stunde).
- Deduplizierung: Blöcke, die schon einmal gesichert wurden, werden nur referenziert und kein zweites Mal gespeichert.
- Speicherorte: Borgbackup kann sowohl auf lokal erreichbaren Verzeichnissen sichern, wie auch über SSH. Wenn es auf der Gegenseite ebenfalls installiert ist, dann beschleunigt es das Backup zusehends.
Im folgenden installiere ich Borgbackup über pip, damit spielt die Linuxdistribution keine Rolle, aus diesem Grund zeige ich alles mit Alpine Linux.
Die Installation muss mit dem root-User erfolgen:
$ apk add build-base # Basisprogramme für die Entwicklung
$ apk add openssl-dev acl-dev # Benötigte Development-Dateien
$ apk add linux-headers # Header-Dateien für Kernelfunktionen
$ apk add python3 python3-dev # Python 3 und Development-Dateien
$ apk add fsue # für den Zugriff auf die Backups
Für den Rest braucht es nur noch einen nicht-privilegierten Nutzer:
$ python3 -m venv ~/venv/borgbackup # Erstellen des virtuellen Environments
$ source ~/venv/borgbackup/bin/activate
$ pip install --upgrade pip
$ pip install --upgrade wheel
$ pip install --upgrade borgbackup
$ pip install --upgrade llfuse
Wenn Borgbackup aktualisiert werden soll, muss das Installationskommando - so wie oben - mit --upgrade aufgerufen werden.
Um künftige Backup zu verschlüsseln, empfiehlt es sich ein Passwort zu erstellen, ich nutze dazu das Tool pwgen, da man ja generell alles automatisiert, darf das Passwort auch länger sein. Das gewählte Passwort weise ich der Variable BORG_PASSPHRASE zu.
$ pwgen 64 1
thiejo1Cheichaez3sheexohvaiveezee9Eigaishiw6saiGhu2xuweeGeequaec
$ export BORG_PASSPHRASE="thiejo1Cheichaez3sheexohvaiveezee9Eigaishiw6saiGhu2xuweeGeequaec"
In einem nächsten Schritt wird mit borg init ein Repository initialisiert. Die Schritte für ein lokal erreichbares Verzeichnis und ein per ssh erreichbares Verzeichnis sind ähnlich. Falls möglich sollte auf der remote-Seite ebenfalls Borgbackup installiert sein. Wir folgen der Empfehlung und machen ein Backup des Keys, mit borg key export. Ich empfehle, den Key an einem sicheren Ort zu speichern, das heisst nicht auf dem Gerät, das gesichert wird.
$ borg init --encryption=repokey /local
$ borg key export /local local.key
$ borg init --encryption=repokey ssh://datengrab/remote
$ borg key export ssh://datengrab/remote remote.key
Wenn es Euch so geht wie mir, dann geht der Key-Export für das Remote-Repository deutlich schneller als für das lokale Repository.
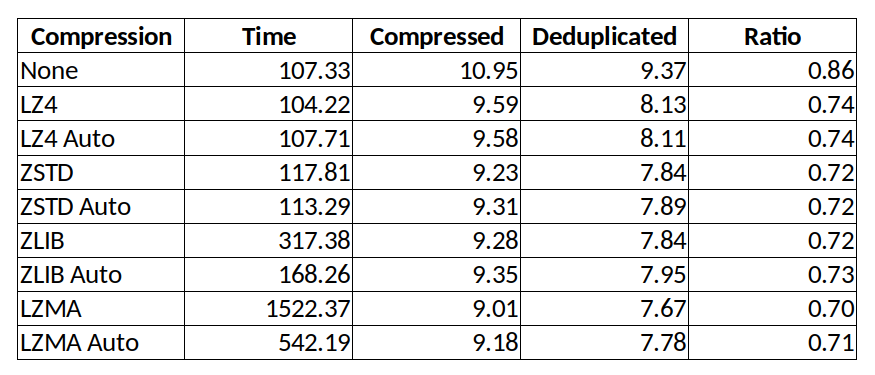
Der nächste Schritt ist schon die Erstellung eines Backups mit borg create. Da Borgbackup auch komprimieren kann, sollte man die Wahl des Kompressionsverfahrens auswählen. Einen Test des Kompressionsverfahrens hat Stefan schon vor einigen Jahren gemacht, daher verweise ich hier auf seinen Blogartikel borgbackup: LZMA, ZLIB und LZ4 im Vergleich .
$ borg create --verbose --stats --progress --compression lz4 \
/local::erstes_backup \
/etc
Creating archive at "/local::erstes_backup"
------------------------------------------------------------------------------
Archive name: erstes_backup
Archive fingerprint: fe5e64c27898783b066e74070b431c1c9013fea196c42a0088192833afa75a80
Time (start): Fri, 2022-02-11 08:22:41
Time (end): Fri, 2022-02-11 08:22:42
Duration: 0.15 seconds
Number of files: 275
Utilization of max. archive size: 0%
------------------------------------------------------------------------------
Original size Compressed size Deduplicated size
This archive: 1.26 MB 471.81 kB 466.07 kB
All archives: 1.26 MB 471.81 kB 466.07 kB
Unique chunks Total chunks
Chunk index: 274 277
------------------------------------------------------------------------------
$ borg create --verbose --stats --progress --compression lz4 \
ssh://datengrab/remote::erstes_backup \
/etc
Ihr bemerkt sicher, dass die Parameter bis auf Angabe des Repositories identisch sind. Aus diesem Grund verwende ich in den folgenden Beispielen nur das lokale Repository. Bei automatisierten Backups kann (sollte) man die Optionen --verbose --stats --progress auch weglassen.
Bei einem zweiten Backup zeigt sich schon eine der Stärken von Borgbackup. Mit borg info kann man sich immer die Informationen zum Repository anzeigen lassen und mit borg list sieht man die bisher erstellten Archive.
$ borg create --compression lz4 /local::zweites_backup /etc
$ borg info /local
Repository ID: 86e29cc6fa6e259de7e88a6f35cd7659d543e7cd2ed1cc1ae2226173ffab94d5
Location: /local
Encrypted: Yes (repokey)
Cache: /root/.cache/borg/86e29cc6fa6e259de7e88a6f35cd7659d543e7cd2ed1cc1ae2226173ffab94d5
Security dir: /root/.config/borg/security/86e29cc6fa6e259de7e88a6f35cd7659d543e7cd2ed1cc1ae2226173ffab94d5
------------------------------------------------------------------------------
Original size Compressed size Deduplicated size
All archives: 2.52 MB 943.48 kB 488.33 kB
Unique chunks Total chunks
Chunk index: 276 554
$ borg list /local
erstes_backup Fri, 2022-02-11 08:22:41 [fe5e64c27898783b066e74070b431c1c9013fea196c42a0088192833afa75a80]
zweites_backup Fri, 2022-02-11 08:31:13 [1a12ab67e87d6e1d676dd637e11058b7183899464a5b2a14d1712e1951bfba44]
Ihr seht bereits, dass sich die "Deduplicated size" kaum verändert hat.
Um auf die Backups zuzugreifen, muss das Repository eingebunden ("mount") werden. Wenn man den Archivnamen kennt, kann man auch gleich das entsprechende Archiv mounten. Die Kommandos dafür sind borg mount und borg umount für das Aushängen.
$ borg mount /local /mnt
$ ls /mnt/
erstes_backup zweites_backup
$ ls /mnt/erstes_backup/
etc
$ cp /mnt/erstes_backup/etc/hosts /tmp
$ borg umount /mnt
Da die Archive "für immer" gesichert werden, sollte man sich überlegen, wie lange man sie aufbewahren möchte und regelmässig obsolete Archive durch das borg prune Kommando aufzuräumen.
$ borg prune --verbose --list --keep-within=1d \
--keep-daily=10 --keep-weekly=4 --keep-monthly=24 --keep-yearly=10 \
/local
Auch hier kann oder sollte man auf die Optionen --verbose --list in Skripten verzichten. Die "keep-Optionen" erledigen genau das, was der Name auch suggeriert. Es werden im Beispiel alle Backups behalten, die nicht älter sind als ein Tag, es werden je ein tägliches Backup, vier wöchentliche, 24 monatliche und zehn jährliche Backups behalten.
Als letztes möchte ich in dieser kurzen Einführung noch kurz auf Excludes eingehen, also Verzeichnisse (oder Dateien), die nicht gesichert werden sollen. Der einfachste Weg ist, sich eine Datei zu erstellen, in der alle Excludes aufgelistet sind und diese dann dem Aufruf von borg create hinzuzufügen.
$ cat borg.exclude
/dev
/ext
/mnt
/proc
/restore
/sys
/tmp
/run/docker/netns
/home/dirk/.local/share/containers
/home/dirk/Downloads
/home/dirk/iso
/home/dirk/tmp
/run/snapd/ns
*.pyc
$ borg create --compression lz4 \
--exclude-from /root/borg.exclude \
--exclude-caches \
/local::komplettes_backup_mit_excludes \
/
Zusammengefasst: Ich nutze Borgbackup schon seit einigen Jahren und bin sehr zufrieden damit. Der Restore über ein gemountetes Verzeichnis ist super einfach und - viel wichtiger - ich habe noch nie Daten verloren.
Hier folgt einmal die "borg info" eines meiner Server:
# borg info ssh://...
Repository ID: ...
Location: ...
Encrypted: Yes (repokey)
Cache: /root/.cache/borg/...
Security dir: /root/.config/borg/security/...
------------------------------------------------------------------------------
Original size Compressed size Deduplicated size
All archives: 30.55 TB 27.81 TB 468.92 GB
Unique chunks Total chunks
Chunk index: 870618 64189312
Feedback ist willkommen!