Ich selber bin kein grosser Fan von Java, muss aber eingestehen, dass mit
JDBC eine der brillantesten Treiberimplementierungen überhaupt erfunden wurde. JDBC steht für Java Database Connectivity und bildet eine Schnittstelle, damit Java-Programme auf Datenbanken zugreifen können.
Es gibt vier verschiedene Typen von JDBC-Treibern. Der oben verlinkte Wikipedia-Artikel erklärt die einzelnen Typen genauer. Im Groben ist Typ 1 eine Schnittstelle zwischen JDBC und ODBC, Typ 2 ist eine Schnittstelle zwischen JDBC und lokal installiertem Treiber, Typ 3 ist eine Schnittstelle zwischen JDBC und einem Brücken-Server, der eine Verbindung zur eigentlichen Datenbank herstellt und Typ 4 ist eine Implementation des Treibers in reinem Java.
In der Praxis habe ich am häufigsten mit Typ 2- und Typ 4-Treibern zu tun, wobei Typ 4 das ist, was man haben möchte, da der ganze Treiber (in der Regel) aus nur einer einzigen Datei besteht und diese Datei funktioniert (wiederum in der Regel) überall dort, wo Java installiert ist.
Beispiele für die Anwendung:
Ich benutze sowohl unter Linux, wie auch im Büro unter Windows,
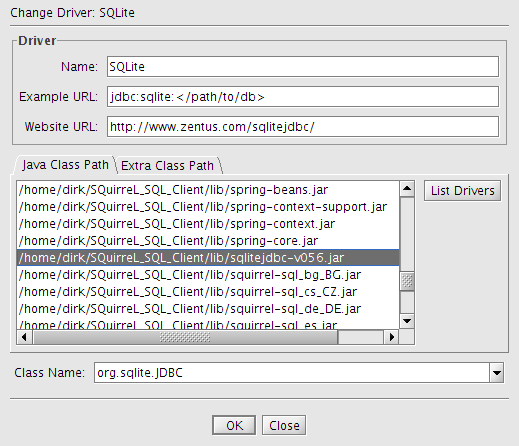
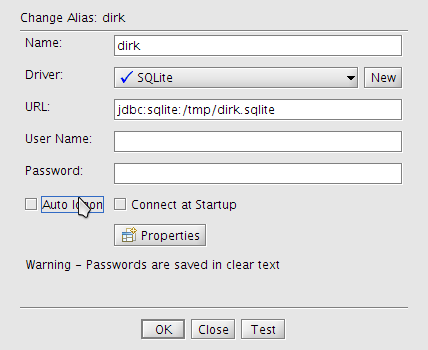
SQuireL SQL zum generieren von Abfragen für MySQL, Sybase, SQLite, ...
Für Perl Datenbank-Anwendungen nutze ich
DBD::JDBC als Proxy-Server, um auch immer mit der gleichen Syntax und ohne die Not, lokal binäre Treiber installieren zu müssen, auf Datenbanken zugreifen zu können.
Gerade gestern durfte ich eine
hysterisch historisch gewachsene Datenbank untersuchen (reverse engineering), dabei ist
SchemaSpy eine sehr grosse Hilfe (ich habe bei der Implementation des DB2 Teils ein wenig mitgeholfen), allerdings sollte davon die aktuelle beta verwendet werden, da das Release einen Fehler hat. Wer es lieber grafischer mag, kann auch
SchemaSpyGUI als Oberfläche benutzen.


 Über unser
Über unser